Yes, in some cases, Yandex can upload files faster than your internet speed. They found a way of warp speeds.
Actually, I just noticed a situation in Yandex Disk and I wanted to post a tiny blog post about a concept; Deduplication.
Everything started with a (public-domain documentary) upload to Yandex Drive. (Years ago Yandex provided +100 GB of storage for free) I was trying to upload 20+ gigabytes of my files. My internet connection speed was 20 mbit/second, which means 2.5 megabytes per second at max. By assuming that I can upload the files at maximum peak, it would take at least, 8192 seconds.
Minimum time to upload with my speed
8192 seconds = 136 minutes = 2 hours 16 minutes
I didn’t measure the actual time, but Yandex managed out to upload the file in less than 3 minutes. And the files appeared in the web portal instantly, I was able to stream the video files with different resolutions. I don’t know how Yandex prepares low resolution versions, but they didn’t even need a time to prepare low-res streamable versions. So I started to google-it the concept.
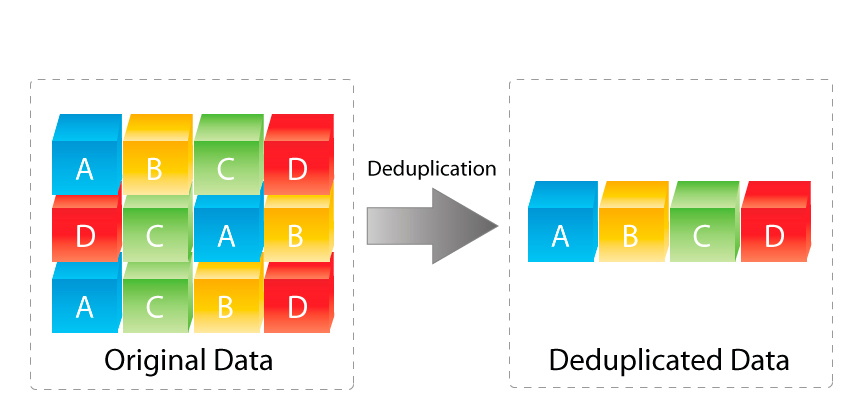
Deduplication is a concept to reduce the disk consumption of the files. When a file is duplicated, it’s expected to consume 2x of disk size. But within a deduplication enabled system, the file system keeps the reference of the original file and copies of the original file linked to this reference. So both network and disk usage can be optimized.

Yandex was not uploading the file in my case. Yandex gets the hash of the file first (like SHA-256). Then checks whether their server contains that file. If it was already existing, they are granting access to the file under my account. With the magic of hashing algorithms, they can be sure about the uniqueness of the data.
An interesting point;
Yandex is not the first one to use deduplication for saving storage. Dropbox was using the same method, and inspired an open source tool Dropship (Github). Here is a section of the readme;
How does it work?
The deduplication scheme used by Dropbox works by breaking files into blocks. Each of these blocks is hashed with the SHA256 algorithm and represented by the digest. Only blocks that are not yet known are uploaded to the server when syncing.
By using the same API as the native client, Dropship pretends to sync a file to the dropbox folder without actually having the contents. This bluff succeeds because the only proof needed server-side is the hash of each 4MB block of the file, which is known. The server then adds the file metadata to the folder, which is, as usual, propagated to all clients. These will then start downloading the file.
Also, I found a feature request for rclone on Github. Which mentions Yandex’s hashing method. Using both algorithms might not be so smart, because a 256-bit hash of SHA-256 is more secure, while MD5 is faster but produced a hash with fewer bits.
What problem are you are trying to solve?
Yandex supports deduplication on file upload - you need to pass the Md5 and Sha256 hashes and the file size to the PUT endpoint, and if a file like that exists anywhere on Yandex - the endpoint answers with “201 Created” and the upload is finished, as the already existing file is made available.
Hashing algorithms produces practically unique, theoretically almost-unique identifiers. So while MD5 would be more limited than the SHA-256 in producing uniqueness, MD5 is a faster method which might allow Yandex Disk application to quickly check the MD5 hash of the files. If they see a match in server, they can check SHA256 for gaining better uniqueness.
Because whenever I try to upload large files, I notice that, Disk application starts with a big CPU and disk usage, then during upload it uses less resource. This should be happening as a result of calculating multiple big file hashes in parallel or serial order.
P.S: I don’t know how Yandex prepares low resolution streams of the file. I guess it should be a server side processing. Maybe a resource-smart realtime web-supported codec. Let’s discover this another time.